在我们学习了设计模式后,一板一眼的记住了示例代码;可是当你翻开源码后,你会发现一切都不是想象中那样……
适读人群
- 具有JAVA基础开发知识
- 接触过HTTP,HTTPS,HTTP2,TCP,Socket等相关知识
- 简单了解设计模式
背景
书接上文,上文书我们有介绍到我们的OKHttp是一个大致的主要的结构是由拦截器串联成一个链条,设计成一个责任链模式去处理;但是其实我们只是告诉读者我们的拦截器会一个个依次调用到,但是其实具体如何一个一个依次调用到并未实际给出解释;设计模式的实例代码我们都敲过,那么今天我们就来对比一下有一个demo和设计模式在实战中到底有怎样的差距!
示例DEMO简单回顾
还记得初学责任链设计模式时老师提到的一个场景,现在记忆犹新:
- 公司里面,请假条的审批过程:
* 如果请假天数小于3天,主任审批
* 如果请假天数大于等于3天,小于10天时,经理审批
* 如果大于等于10天,小于30天,总经理审批
* 如果大于等于30天,直接提示拒绝
做出的一个UML图就是这个样子
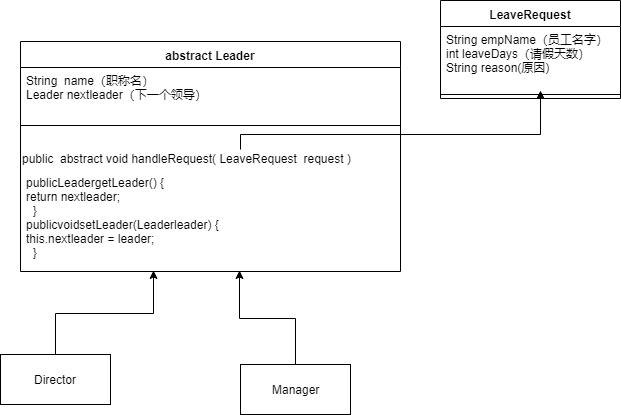 定义一个请假请求类
定义一个请假请求类
public class LeaveRequest {
String empName;
int leaveDays;
String reason;
public LeaveRequest(String empName, int leaveDays, String reason) {
super();
this.empName = empName;
this.leaveDays = leaveDays;
this.reason = reason;
}
//省略getter setter
}
根据以上场景抽象出一个leader的抽象类是这样的:
public abstract class Leader {
protected String name;
protected Leader nextleader;
public Leader(String name) {
super();
this.name = name;
}
/**
*定义抽象类处理请求
**/
public abstract void handleRequest(LeaveRequest request);
public Leader getLeader() {
return nextleader;
}
public void setLeader(Leader leader) {
this.nextleader = leader;
}
}
接下来我们简单定义实现类: 主任
public class Director extends Leader {
public Director(String name) {
super(name);
}
@Override
public void handleRequest(LeaveRequest request) {
if(request.getLeaveDays() <10){
System.out.println("主任批准"+request.empName+"天数"+request.leaveDays);
}else {
Objects.requireNonNull(request);
Objects.requireNonNull(nextleader);
nextleader.handleRequest(request);
}
}
}
经理
public class Manager extends Leader {
public Manager(String name) {
super(name);
}
@Override
public void handleRequest(LeaveRequest request) {
if(request.getLeaveDays() <30){
System.out.println("经理批准"+request.empName+"天数"+request.leaveDays);
}else {
System.out.println("是不是不想干了");
}
}
}
调用示例
public static void main(String[] args) {
LeaveRequest request = new LeaveRequest("大头", 6, "回家乡");
LeaveRequest request2 = new LeaveRequest("小头", 15, "去台湾");
//创建责任链的类
Director director = new Director("王大佬");
Manager manager = new Manager("李大佬");
//将类通过setter关联起来
director.setLeader(manager);
//从责任链第一个类调用起来,将request传入
director.handleRequest(request);
director.handleRequest(request2);
}
结果:
主任批准大头天数6
经理批准小头天数15
到这里一个简单责任链的设计模式示例就结束了,网上的许多示例到此也就真的结束了;或许比较贴心的文章会告诉读者,我们的责任链的遍历可以有很多种,除了使用链表还可以使用其他数据结构比如使用数组;再贴心一点的文章或许会把数组形式的示例分享出来,可是到底这么多种实现到底有何不同呢?到底其优劣到底是怎样的,场景又是如何呢?今天笔者借着OKhttp的源码希望帮助大家有更直观的认识!
RealInterceptorChain分析
首先来看一下我们interceptor和chain的一个定义
拦截器接口定义
public interface Interceptor {
Response intercept(Chain chain) throws IOException;
}
chain的接口定义
interface Chain {
/**
* 获取当前处理过后的request
*/
Request request();
/**
* 用于调用拦截器链的下一个对象
*/
Response proceed(Request request) throws IOException;
/**
网络层级拦截器可以获得到 连接,应用层返回空
*/
@Nullable Connection connection();
/**
* 请求网络收到响应过程的一个抽象出的一个对象
*/
Call call();
/**
* 各类连接读写超时时间的读取与设置
*/
int connectTimeoutMillis();
Chain withConnectTimeout(int timeout, TimeUnit unit);
int readTimeoutMillis();
Chain withReadTimeout(int timeout, TimeUnit unit);
int writeTimeoutMillis();
Chain withWriteTimeout(int timeout, TimeUnit unit);
}
为了强调两者的强关联性,chain被定义为了一个内部类
public interface Interceptor {
//..
interface Chain {
//..
}
RealInterceptorChain实现方式解析
首先看一下,当前 chain的接口的实现类RealInterceptorChain的构造方法
public final class RealInterceptorChain implements Interceptor.Chain {
/**
*整个责任链由一个数组组成
**/
private final List<Interceptor> interceptors;
//利用index指向当前执行到哪一个 interceptors
private final int index;
/**
* 针对拦截器链上的每一个Interceptor都可以很方便读取下方所有的对象,后期添加一些属性时,每一个持有当前
chain对象的interceptors都可以读取到
**/
private final Transmitter transmitter;
private final @Nullable Exchange exchange;
private final Request request;
private final Call call;
private final int connectTimeout;
private final int readTimeout;
private final int writeTimeout;
private int calls;
public RealInterceptorChain(List<Interceptor> interceptors, Transmitter transmitter,
@Nullable Exchange exchange, int index, Request request, Call call,
int connectTimeout, int readTimeout, int writeTimeout) {
this.interceptors = interceptors;
this.transmitter = transmitter;
this.exchange = exchange;
this.index = index;
this.request = request;
this.call = call;
this.connectTimeout = connectTimeout;
this.readTimeout = readTimeout;
this.writeTimeout = writeTimeout;
}
}
由以上代码结合上篇 OkHttp源码分析 初识结构篇(一)的知识,我们可以看到okHttp实际核心就是
Response getResponseWithInterceptorChain() throws IOException {
//定义拦截器数组
List<Interceptor> interceptors = new ArrayList<>();
//添加拦截器
interceptors.addAll(client.interceptors());
interceptors.add(new SomeOkHttpInterceptor());
interceptors.addAll(client.networkInterceptors());
//使用 chain将链串联起来
Interceptor.Chain chain = new RealInterceptorChain(interceptors, transmitter, null,
//传入index
0,
originalRequest, this, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
//触发第一个拦截器
Response response = chain.proceed(originalRequest);
}
利用数组和一个index依次遍历执行,每一个interceptor在进入 intercept方法体后
private static class LoggingInterceptor implements Interceptor {
@Override public Response intercept(Chain chain) throws IOException {
long t1 = System.nanoTime();
//获取到request
Request request = chain.request();
//获取到 url,connection,header等
logger.info(String.format("Sending request %s on %s%n%s",
request.url(), chain.connection(), request.headers()));
Response response = chain.proceed(request);
long t2 = System.nanoTime();
logger.info(String.format("Received response for %s in %.1fms%n%s",
request.url(), (t2 - t1) / 1e6d, response.headers()));
return response;
}
}
由上文的 LoggingInterceptor可以看到,我们可以通过chain得到一切okhttp想开放给我们的对象,非常便利方便!
chain.proceed(request)解析
上面看完一个Chain类构造和遍历拦截器的思路,那么接下来我们快速看一下代码实现(排除保护异常情况的代码)
public Response proceed(Request request) throws IOException {
// 创建新的chain类 Call the next interceptor in the chain.
RealInterceptorChain next = new RealInterceptorChain(interceptors, transmitter, exchange,
index + 1, request, call, connectTimeout, readTimeout, writeTimeout);
//取出当前拦截器对象
Interceptor interceptor = interceptors.get(index);
//将构造好的下一个chain传递给interceptor
Response response = interceptor.intercept(next);
//返回最终的response
return response;
}
由以上代码可以得知,每一个拦截器中调用chain.proceed时,都会引起下一个将index加一然后依次从数组遍历到下一个,同样实现了我们的责任链的设计模式
思路对比
数组形式实现
数组方式优点:
我们可以看到两者一个思路区别,示例demo使用了链表的形式,Okhttp是采用了数组的形式;那么两者的实战使用上会有一个怎样的优劣取舍呢?下面我们来根据OKhttp的场景的需求分析一下:
OKHTTP:
- 由于设计整个OKhttp的核心都是由拦截器搭建而成,所以要大量有new interceptor()被调用;而无论用户的还是OKhttp自己部分的拦截器显然使用链表非常不便大量添加
//类似这样的addAll操作
interceptors.addAll(client.interceptors());
interceptors.add(new RetryAndFollowUpInterceptor(client));
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
//类似这样的addAll操作
interceptors.addAll(client.networkInterceptors());
interceptors.add(new CallServerInterceptor(forWebSocket));
- 每一个拦截器都要可以共享一些数据,比如读写超时,当前的socket相关内容详情可以见上文的LoggingInterceptor,展示出了很多interceptor可以调用到的对象,也很方便后期再添加更多的对象,并且像OKhttp是定义interceptors为接口
public interface Interceptor {
Response intercept(Chain chain) throws IOException;
}
如果用类似demo示例那种抽象类,传值修改构造方法无疑要大动干戈,而OKhttp的做法是怎样的呢?
public RealInterceptorChain(List<Interceptor> interceptors, Transmitter transmitter,
@Nullable Exchange exchange, int index, Request request, Call call,
int connectTimeout, int readTimeout, int writeTimeout) {
//忽略赋值成员变量
}
定义chain对象,将需要共享的元素封装到一个chain中,将chain传入interceptor让其数据包裹chain中,避免其因为数据的增加而频繁改动代码,类似Visitor Pattern,当需要改动增加共享的数据时,只需要改动chain的构造方法,而这个chain的创建只有
Response getResponseWithInterceptorChain() throws IOException {
Interceptor.Chain chain = new RealInterceptorChain(interceptors, transmitter, null, 0,
originalRequest, this, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
}
在getResponseWithInterceptorChain()这个方法作为驱动第一个拦截器回调需要创建一次后,剩下的都是在chain的内部调用构造方法创建,改动量的成本都是极小的!
链表形式实现
java.util.logging.Logger#log()
来一段简易代码快速了解一下
public void log(LogRecord record) {
//部分代码忽略
Logger logger = this;
//不断循环获取 logger的父节点,直到获取到系统定义的logger,即最终的root logger
while (logger != null) {
//取出logger中的handler,将一条一条的日志记录推进去,处理输出到各个地方
final Handler[] loggerHandlers = isSystemLogger
? logger.accessCheckedHandlers()
: logger.getHandlers();
for (Handler handler : loggerHandlers) {
handler.publish(record);
}
//部分代码忽略
logger = isSystemLogger ? logger.parent : logger.getParent();
}
}
//日志信息抽象出的一个对象,记录日志的级别,名字,内容等
class LogRecord{
//忽略
}
//可以理解成是 用于处理日志输出到哪里为抽象类 继承可以输出到比如 控制台,文件,网页上
abstract class Handler{
//忽略
}
虽然logger在jdk中的数据结构是一个树状的,但是,每一条日志都会经过上述该方法,从我们用户定义的子节点logger一直遍历回到系统定义的根节点;其实笔者认为就是一个简单 责任链设计模式,将日志记录不断分发到每一层级,做不同的输出
链表形式优点:
- 结构简单,不需要维护多余的类,适用于责任链长度不会过长的情况
很明显我们一般的输出日志的情况,文件流,控制台,最多可能我们需要自定义输出到网页上远程查看,故形式不会过于多样,甚至大多情况我们使用系统自带的就基本够用了!所以层级不会过深,不存在需要大量添加的情况,故能够做到维护更少的内容,结构简单使用链表足矣!
实战中的使用反例
这个设计模式笔者在很早以前就有学到过,很跃跃欲试想在自己实际的代码中使用,下面就分享一个学艺不精,使用不当的情况我遇到了这样一个需求: 笔者的负责的app是一个类似滴滴的司机端一样的项目,需求就是组件司机在抢单后,提交订单前这段时间的一个UI交互,然后处理这样的一个情况:
首先,是司机抢到订单,进入自己的订单详情界面,然后就是部分需求,一图以蔽之
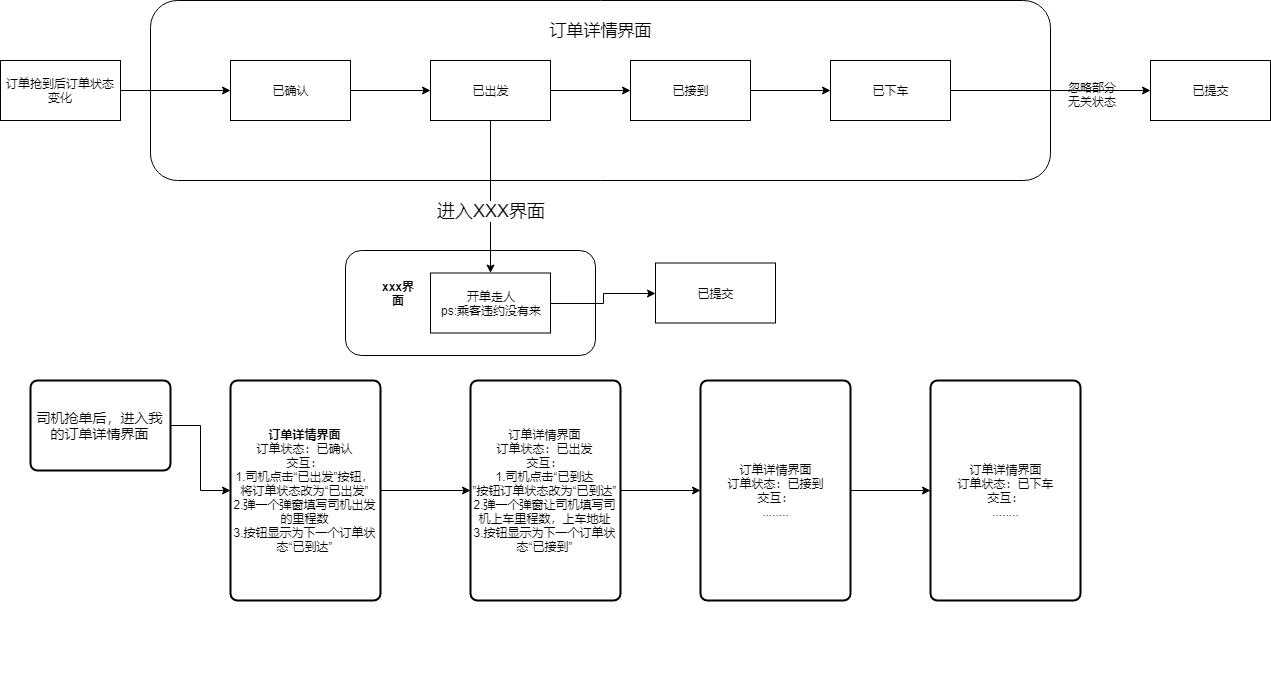
大家不用很细致的了解,简单概括就是订单详情界面包含大量更新订单状态操作与交付,里面设有有很多弹窗形式表单需要司机在不同订单状态下确认或填写很多订单相关信息。
错误的设计思路
由于每一个订单状态下,app的交互由上图可知都是弹出不同弹窗,以及一些不同状态下展示的一些小按钮,将每一步的交互抽象成一组统一的类用链表串联起来,我理想的状态是这样的
 因为司机违约的情况属于别的界面,故想只把上图这部分内容抽象为一个 责任链形式,每一个链条就是 一个订单状态下,该订单详情界面所有的交互抽象成的一个对象
因为司机违约的情况属于别的界面,故想只把上图这部分内容抽象为一个 责任链形式,每一个链条就是 一个订单状态下,该订单详情界面所有的交互抽象成的一个对象
实际的现实情况
但是,实际上初识设计模式的我完全没有考虑一个很明显的点就是,现实中订单的状态应该是下图

设计问题:
- 订单状态本来就不是个线性的链表形式,而是如上图一样可能在每一个订单状态下产生正常或者异常两种分支状态
- 逻辑上说不通,不管是“已出发”,还是“开单走人”都是订单状态的一种不应该割裂开分析
- 后期如果其他订单状态下,有异常的订单状态产生分支以后这样的设计非常难以维护
为了这样的不良设计,后期的维护吃了很多苦头!
教训心得
- 在对需求了解不全时,切勿随意抽象设计
- 使用设计模式一定要注意应对场景(像订单状态这种很明显有多种正常或者异常状态的情况,很明显是不适合这种更适合应对线性情况的设计模式)
总结
说了这么多,更多是希望我们一起能看懂OO编程,攻克设计模式;让我们的自己写的业务代码也可以有设计的美感,而非只是一个就会简单调用搬砖的码农!
NEW FEATURE
- RetryAndFollowUpInterceptor重试重定向的分析
- BridgeInterceptor的分析
- CacheInterceptor缓存机制分析
- ConnectInterceptor连接复用相关分析
- CallServerInterceptor实际IO操作分析
- OKhttp同步与异步calls的调用管理分析
- DNS简析