只有读过网络请求框架源码,你才知道发送一个请求到底有多么复杂……
适读人群
- 具有JAVA基础开发知识
- 接触过HTTP,HTTPS,HTTP2,TCP,Socket等相关知识
- 简单了解设计模式
背景
从Google开始摒弃了httpclient替换为了Okhttp后,Android的网络请求世界 Retrofit2 + RxJava也在大行其道时;OkHttp无疑成为了大家公认好评的新一代网络请求框架;但是,笔者认为一个框架的优劣不能只是因为其流行就裁定它一定是当前最适合我们自己的工具;应该一切都有我们自己的判断,只有我们自己能够说出的它的优势劣势我们才可以真正的用好这些框架;基于此种目的打算对OKhttp一探究竟……
GET STRATED
首先来快速了解一下OKhttp,它是一个能够帮助我们在交换数据和媒体时,载入速度更快且节省网络带宽的HTTP客户端; okhttp支持
同步调用
我们 GET 示例
public class GetExample {
//构建一个 OkHttpClient的实例
OkHttpClient client = new OkHttpClient();
String run(String url) throws IOException {
//构建一个 request 网络请求,传入定义的url
Request request = new Request.Builder()
.url(url)
.build();
//传入client,调用excute进行执行获取到用户需要的响应
try (Response response = client.newCall(request).execute()) {
return response.body().string();
}
}
}
POST 示例
//定义MediaType
public static final MediaType JSON
= MediaType.get("application/json; charset=utf-8");
//初始化 OKhttpClient
OkHttpClient client = new OkHttpClient();
String post(String url, String json) throws IOException {
//针对requestBody进行初始化
RequestBody body = RequestBody.create(JSON, json);
//传入对应的url和body,构建
Request request = new Request.Builder()
.url(url)
.post(body)
.build();
Call call = client.newCall(request);
try (Response response = call.execute()) {
return response.body().string();
}
}
初识OKhttp
首先,了解了上文的示例,我们对于OKhttp的API调用有了一个初步的认识,接下来简单介绍一下我们刚才所用到一些类
okhttpClient的说明图,request说明图,response说明图,call说明图
由此我们便可以初步的了解了OkHttp的简单调用和与用户最常打交道的几个类;接下来我们针对上文的示例代码做一个初步的流程分析,让大家有一个简单对于OKhttp的工作流程有一个大致的了解
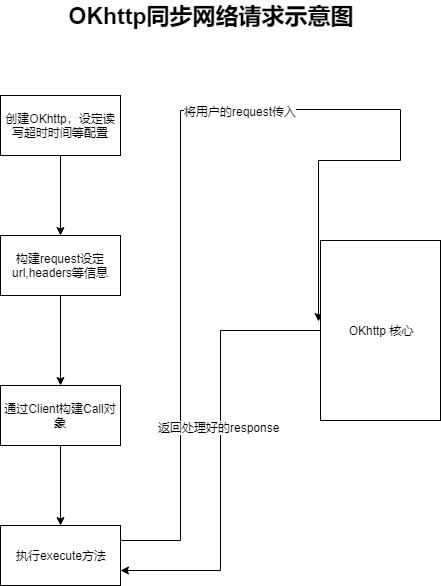
所以,通过此图我们可以大致的了解到关于OKhttp最粗略的一个流程,在call中有一个execute的方法;而其中最核心的就是这个方法 ;所有的网络请求的整个处理核心就在这个部分;所以接下来我们的重心就是这里
Interceptor
在分析前我们需要了解一下OKhttp在框架中引入的一个概念 interceptor (拦截器),它的作用机制非常强大,可以监控,重写,重复调用;借用官网的一个示例简单了解一下用法
class LoggingInterceptor implements Interceptor {
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
//获取拦截器链中的request
Request request = chain.request();
//记录 request相关信息
long t1 = System.nanoTime();
logger.info(String.format("Sending request %s on %s%n%s",
request.url(), chain.connection(), request.headers()));
Response response = chain.proceed(request);
long t2 = System.nanoTime();
logger.info(String.format("Received response for %s in %.1fms%n%s",
response.request().url(), (t2 - t1) / 1e6d, response.headers()));
return response;
}
}
此为一个日志拦截器的定义,而这个拦截器最关键的部分就是 chain.proceed(request)这个就是我们的http交互产生对应当前的request的response的部分;这些拦截器会被串联起来依照顺序依次调用,此处引用下官方文档说明:
A call to chain.proceed(request) is a critical part of each interceptor’s implementation. This simple-looking method is where all the HTTP work happens, producing a response to satisfy the request.
对chain.proceed(请求)的调用是每个拦截器实现的关键部分。这个看起来很简单的方法是所有HTTP工作发生的地方,它生成一个响应来满足请求。
Interceptors can be chained. Suppose you have both a compressing interceptor and a checksumming interceptor: you’ll need to decide whether data is compressed and then checksummed, or checksummed and then compressed. OkHttp uses lists to track interceptors, and interceptors are called in order.
拦截器可以链接。假设您同时拥有压缩拦截器和校验和拦截器:您需要确定数据是否已压缩,然后进行校验和,校验和再压缩。 OkHttp使用列表来跟踪拦截器,并按顺序调用拦截器。
然后,大概了解一下两个概念,就是 OKhttp提供了两种拦截器 :
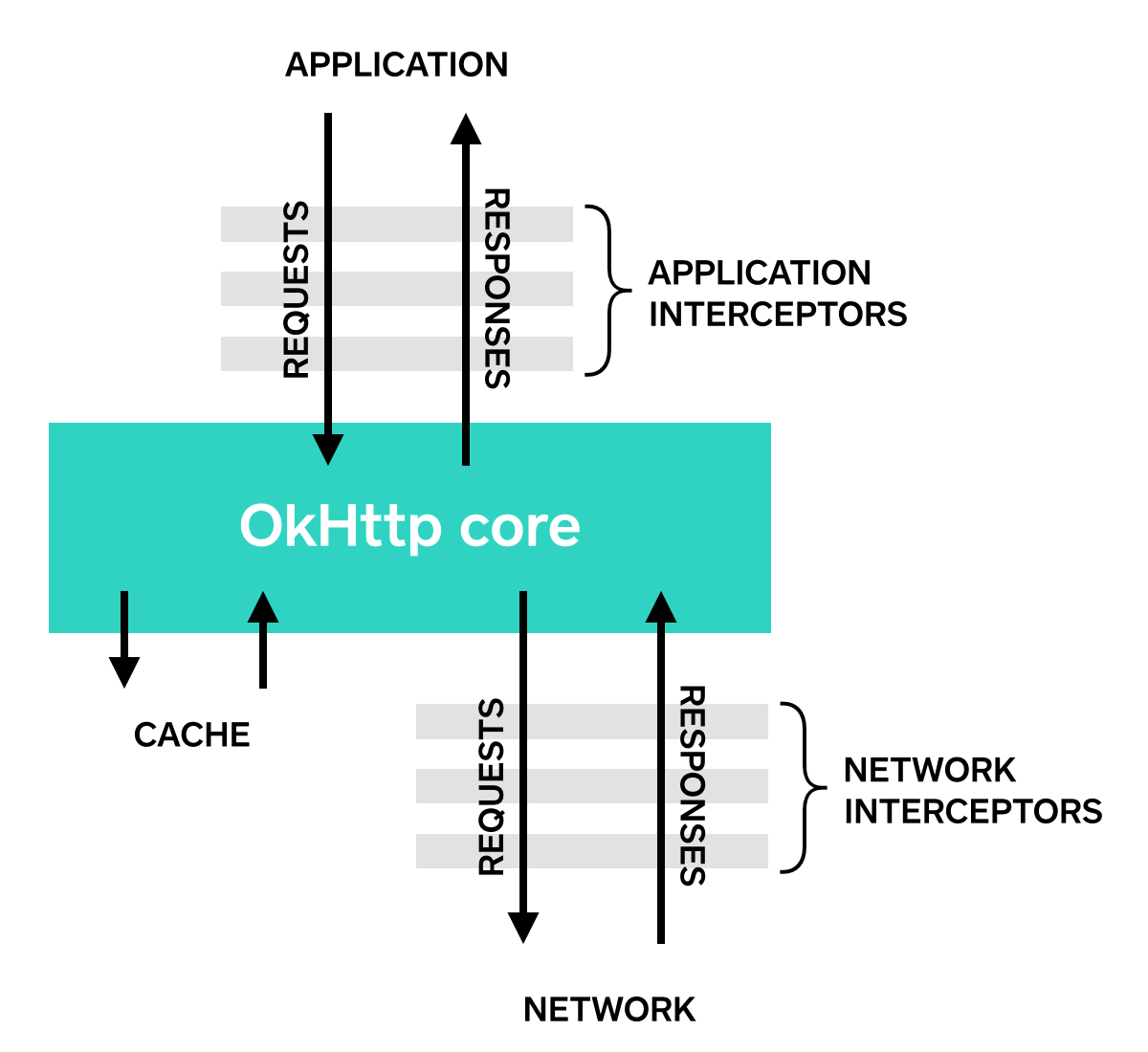
- 应用级别拦截器:只会调用一次,获取到最终的response结果
- 网络级别拦截器:可以感知到网络的请求的重定向,以及重试会被执行多次
引用两个代码示例,让我们简单感受一下两者的区别,具体示例代码详细分析可以查看 interceptors
应用级别拦截器
OkHttpClient client = new OkHttpClient.Builder()
//添加了上文的日志拦截器 (应用级别拦截器)
.addInterceptor(new LoggingInterceptor())
.build();
//添加url以及header
Request request = new Request.Builder()
.url("http://www.publicobject.com/helloworld.txt")
.header("User-Agent", "OkHttp Example")
.build();
Response response = client.newCall(request).execute();
response.body().close();
结果展示:
INFO: Sending request http://www.publicobject.com/helloworld.txt on null
User-Agent: OkHttp Example
INFO: Received response for https://publicobject.com/helloworld.txt in 1179.7ms
Server: nginx/1.4.6 (Ubuntu)
Content-Type: text/plain
Content-Length: 1759
Connection: keep-alive
从结果可以发现,我们的是得到一个最终的结果
网络级别拦截器
OkHttpClient client = new OkHttpClient.Builder()
//添加了上文的日志拦截器 (网络级别拦截器)
.addNetworkInterceptor(new LoggingInterceptor())
.build();
Request request = new Request.Builder()
.url("http://www.publicobject.com/helloworld.txt")
.header("User-Agent", "OkHttp Example")
.build();
Response response = client.newCall(request).execute();
response.body().close();
结果展示:
INFO: Sending request http://www.publicobject.com/helloworld.txt on Connection{www.publicobject.com:80, proxy=DIRECT hostAddress=54.187.32.157 cipherSuite=none protocol=http/1.1}
User-Agent: OkHttp Example
Host: www.publicobject.com
Connection: Keep-Alive
Accept-Encoding: gzip
INFO: Received response for http://www.publicobject.com/helloworld.txt in 115.6ms
Server: nginx/1.4.6 (Ubuntu)
Content-Type: text/html
Content-Length: 193
Connection: keep-alive
Location: https://publicobject.com/helloworld.txt
INFO: Sending request https://publicobject.com/helloworld.txt on Connection{publicobject.com:443, proxy=DIRECT hostAddress=54.187.32.157 cipherSuite=TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA protocol=http/1.1}
User-Agent: OkHttp Example
Host: publicobject.com
Connection: Keep-Alive
Accept-Encoding: gzip
INFO: Received response for https://publicobject.com/helloworld.txt in 80.9ms
Server: nginx/1.4.6 (Ubuntu)
Content-Type: text/plain
Content-Length: 1759
Connection: keep-alive
从此结果可以看到,我们每次网络发生比如上文的重定向的情况,都可以清楚的感知到 ;初始的一次请求的是http://www.publicobject.com/helloworld.txt,另外一次重定向到了 https://publicobject.com/helloworld.txt.
核心主流程分析——拦截器组合使用
上文我们知道了拦截器这个概念,实际上OKhttp不仅提供用户可以编辑的添加的Interceptor,实际上整个的OKhttp的网络请求整体都是通过一个个的拦截器分层完成的,那么接下来我们把上面的示意图再次拓展更详细些
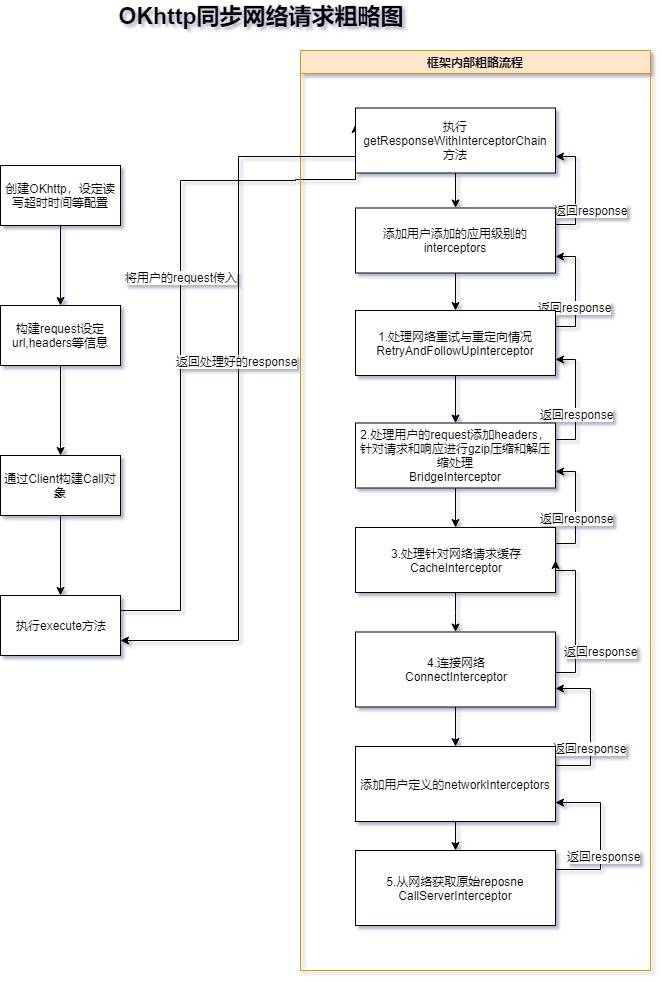
那么来根据此示意图可以看的出,其实我们的网络请求的过程被分解成了一个个的步骤分别分工在每一个类里面去执行,每一个类只负责自己部分工作内容,也就是我们常说的责任链模式(chain-of-responsibility-pattern)并且还在责任链的两个位置提供添加用户的自定义拦截器由此方便针对request和response进行各种自定义的处理,接下来我们来看一下源码部分的实现: 首先是用户调用部分:
用户定义了request,传入了定义好的一个client;并且调用了execute方法
//定义client
OkHttpClient client = new OkHttpClient.Builder()
//添加用户的拦截器
.addInterceptor(new LoggingInterceptor())
.addNetworkInterceptor(new LoggingInterceptor())
.build();
//开始执行网络请求
try (Response response = client.newCall(request).execute()) {
return response.body().string();
}
调用了此时execute最核心的代码:
@Override public Response execute() throws IOException {
synchronized (this) {
//暂时忽略部分
//执行响应链
return getResponseWithInterceptorChain();
//暂时忽略部分
}
拦截器链的调用:
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
//重试之前添加的拦截器,由于 重试层将网络请求全部处理完毕后,才返回;所以是无感知的,用户的拦截器只会得到一个结果
interceptors.addAll(client.interceptors());
//重试重定向拦截器
interceptors.add(new RetryAndFollowUpInterceptor(client));
//给request添加网络请求必须的header,处理request的response的压缩和解压缩
interceptors.add(new BridgeInterceptor(client.cookieJar()));
//处理网路的缓存的部分
interceptors.add(new CacheInterceptor(client.internalCache()));
//创建或者从连接池中找到合适的安全的连接
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
//网络层的拦截器,由于在重试层之下;所以,每次的重试重定向都会有感知,并且所以此时用户添加的 网络级别的 拦截器 就会调用多次
interceptors.addAll(client.networkInterceptors());
}
//执行实际的io流,request和resopnse的接收
interceptors.add(new CallServerInterceptor(forWebSocket));
//定义 串联拦截的链对象,将拦截器串联起来
Interceptor.Chain chain = new RealInterceptorChain(interceptors, transmitter, null, 0,
originalRequest, this, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
//忽略
try {
//依次执行拦截器
Response response = chain.proceed(originalRequest);
//忽略
return response;
} catch (IOException e) {
//忽略
} finally {
//忽略
}
}
然后,需要补充说明一点的是:
上面在getResponseWithInterceptorChain()调用中
interceptors.addAll(client.interceptors());
以及
interceptors.addAll(client.networkInterceptors());
都是在上述代码:
OkHttpClient client = new OkHttpClient.Builder()
//添加用户的拦截器
.addInterceptor(new LoggingInterceptor())
.addNetworkInterceptor(new LoggingInterceptor())
.build();
由用户添加进来的 被okHttpClient缓存到了自己的成员变量中
public class OkHttpClient implements Cloneable, Call.Factory, WebSocket.Factory {
final List<Interceptor> interceptors;
final List<Interceptor> networkInterceptors;
}
实战篇
学习源码如果只是将我们看到的源码进行翻译,其实就失去了学习的意义;因为在我们实际生活用不到迟早还是会忘记和没有学习一样;所以,笔者为大家提供几种我在公司中针对拦截器的实际应用方式,让大家感受一下OKHttp通过拦截器的方式给大家提供便利性的作用
招式一: 记录网络信息
背景
笔者的公司在开发过程中经常和后台对接网络接口时,经常会有这样的对话(PS:笔者负责的app对接的接口有对接加密):
笔者: XXX接口逻辑有问题
后台: 麻烦把明文的报文和加密的报文都发一下,调试一下
笔者: xxx接口的request 是.... ,response是.......
方案
首先,根据上面的场景,看得出我们一般都会有需要时刻获取到每一条请求的明文和密文的情况;所以,一般我们想到的最直接的办法就是解决以上情况的方式就是将request和response的内容都打在控制台上,方便可以随时复制;那么这种场景很明显就可以用Interceptor来解决问题,那么这个解决思路如下:
1.根据当前场景,我们要首先有一个对请求响应处理加解密的 application级别的interceptor(ps:加解密只需要进行一次,故不选择网络级别拦截器) 2.根据我们上文我们可以知道,拦截器链上依此按照每一个拦截器添加的顺序依次执行的,故我们的思路就是在加密拦截器前后各添加一个记录日志的拦截器,从而得到两种请求
代码如下:
OkHttpClient client = new OkHttpClient.Builder()
//添加了明文的日志拦截器
.addInterceptor(new ClearTextLoggingInterceptor())
//添加了加解密
.addInterceptor(new CodecInterceptor())
//添加了密文的日志拦截器
.addInterceptor(new EncrypteLoggingInterceptor())
.build();
为了方便理解可以看一下示意图
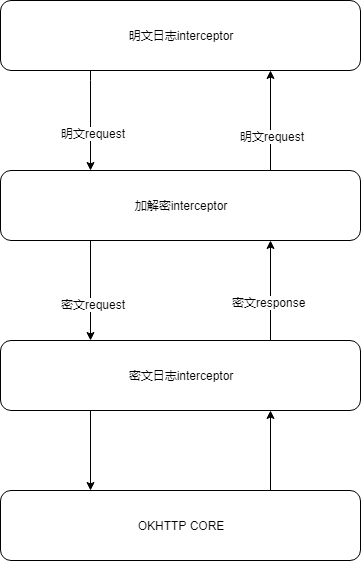
由此我们可以感觉到这种责任链的模式给我们提供的对于 request和response的丰富的客户化拓展性,并且我们可以通过这样的方式将我们想要定制化的效果也分工在每一个类中,然后按照顺序依次执行;这样有以下的好处:
- 当客户化的功能被拆分在每一个拦截器后,方便用户在后期维护中针对功能的增加或者减少
- 提供了每一个类的清晰的可读性,不用把大量的客户化代码都放置到一个类
招式二 用户请求偷天换日李代桃僵
背景
在笔者在公司以下一系列问题:
- 公司由于是to B的业务较多;业务逻辑非常复杂,为我们的app制造数据成了一个成本非常高的问题
- 我们的后台人员资源不足导致我们并行开发对接时,接口给到的时间也经常比较晚,造成前端开发人员时间前松后紧
- 笔者同时还在负责着一部分的app的自动化测试,同样的数据问题限制着UI自动化的进行,致使脚本运行前会需要做大量准备工作,准备好app需要消费的数据
而业界比较公认的一种解决这类问题的方案就是 MOCK数据
但是,当尝试解决此问题时,又有了一只新的拦路虎产生,那就是app的网络请求是加密的,并且由于历史原因各个app的加密方案还不一样,这两者造成的伤害就十分巨大了;因为它会产生这样的以下问题:
- 如果加密方案是一致的,用一个比较简单粗暴的方式就是将我们的加解密方案,在我们自己搭建的mock平台客户化后移植进去,且针对不同项目还要加解密的key配置不一样的
- app要做到多套baseUrl的自由切换,实现mock与真实的请求的互动,又或者可以在wifi中搭建代理服务器帮助切换真实和MOCK的数据,但是两者都具有高昂的成本
方案
所以,基于以上的背景,我们考虑在服务端去解决这样的问题,虽然实现了可以做到客户端无感知,且代码没有入侵性;但是实际上确实付出的代价十分高昂,故我们设计这样的方案:
首先,我们知道
Response response = client.newCall(request).execute()
实际是被这样的一层一层的拦截器处理过后,才返回给用户的response
interceptors.addAll(client.interceptors());
interceptors.add(new RetryAndFollowUpInterceptor(client));
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
interceptors.addAll(client.networkInterceptors());
interceptors.add(new CallServerInterceptor(forWebSocket));
而在拦截器中
class SomeInterceptor implements Interceptor {
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
Request request = chain.request();
//调用此行代码去链式调用下一个拦截器
Response response = chain.proceed(request);
return response;
}
所以,我们可以得到一个结论就是,每一个拦截器可以决定我的是否要链式调用下一层的拦截器,同时也可以决定我这一层的拦截器response数据来自哪里,所以我们有了以下的方案:

从图上可以看到用户的request经过了一些常规的拦截器后,在我们的加解密拦截器前添加了一个mock拦截器,在判断了用户的请求是否需要走mock后,决定用户的response是从真实网络请求中获取,还是从mock server的平台获取,而这个思路充分体现了 责任链模式中,由责任链的每一环节决定分配的任务是否是由自己处理还是分发给下一层处理,而对调用者来说这些都是透明毫无感知的!
转换成代码
class MockInterceptor implements Interceptor {
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
Request request = chain.request();
//判断是否需要mock
if(isNeedMock(request)){
//读取原始request构建对应的MOCK server的request
Request mockRequest = buildMockRequest(request);
//访问mockServer
return MockServer(mockRequest);
}
//调用此行代码去链式调用下一个拦截器
Response response = chain.proceed(request);
return response;
}
private boolean isNeedMock(){
/*此方法主要是用来控制哪些request走假数据,哪些request走真实数据,方便开发自己切换;读者可以根据自己需求自行设计,笔者此处仅提供一个思路*/
}
private Request buildMockRequest( Request request){
/*该方法的主要作用在于我们要把真实的request替换成访问我们自行搭建的mock server平台的请求,一般是替换掉请求的baseUrl部分(即ip地址部分);其他的替换根据读者选用的mock平台自行决定
*/
}
/**
*这一部分的就非常简单了,发送一个网络请求给 mockServer把mockServer的response返回用户
**/
private Response MockServer(Request request) throw Exeption{
return client.newCall(request).execute());
}
此种方案的优劣如下
优势:
-
MOCK SERVER 平台根据项目情况自行选择,由于不需要关心app的本身加密解密,那么基本很多MOCK平台的初始功能就能满足需要,节省了大量了阅读开源mock平台的时间,以及在平台对接各个app加解密的时间
-
真实的接口和mock接口切换靠app端自行代码中随意切换,具体策略由移动端开发人员自己设计;对于大部分移动端同学来说在自己代码中嵌入一些内容,相比搭建代理服务器在并且在服务器的工程写后台代码耗费的时间成本,精力成本远远小的多
-
基于okhttp的拦截器设计,方便随时随时添加移除;对于调用者却毫无感知!这意味着一旦产生问题,或者需要有所改动,我们所有关注点只需要集中在mock拦截器上,代码维护成本十分低廉!
劣势:
-
需要在业务代码中嵌入一些方便开发者使用的工具有一定的侵入性和危险性;这部分如果我们有一个合理的开关,可以控制危险到一个可控范围
-
跳过了不同app的加密部分的问题,但是每一个要用mockServer的app都需要做相类似的定制化操作;不过,如果经过良好的设计,这部分完全可以考虑提取成一个类库方便其他app集成,这样便可以大大降低风险
当然还要搭建一个合适的mock平台,笔者选用的是 EASY-MOCK,感兴趣的同学可以自行了解下~
至此,OKhttp最主要的流程就是此部分的内容,欲知后事如何且听下回分解
NEW FEATURE
- 责任链RealInterceptorChain如何实现对于拦截器的串联
- RetryAndFollowUpInterceptor重试重定向的分析
- BridgeInterceptor的分析
- CacheInterceptor缓存机制分析
- ConnectInterceptor连接复用相关分析
- CallServerInterceptor实际IO操作分析
- OKhttp同步与异步calls的调用管理分析
- DNS简析